Método de estratificación
Identificación de datos atípicos
Para hacer cumplir la definición de los límites en el método de estratificación [véase: Método de estratificación de Dalenius & Hodges] y el número óptimo de clases basados en la media aritmética, es importante la identificación de datos atípicos porque podrían ocasionar resultados poco adecuados. Para contrarrestar este problema, Hubert y Vandervieren (2007) proponen el método de caja, el cual toma en cuenta el grado de asimetría de un conjunto de datos.
\[\left[Q_{1} - 1.5e^{-4MC} IQR; \hspace{0.5cm} Q_{3} + 1.5e^{-4MC} IQR \right] \text{para } MC \geq 0\]
\[\left[Q_{1} - 1.5e^{-3MC} IQR; \hspace{0.5cm} Q_{3} + 1.5e^{-3MC} IQR \right] \text{para } MC < 0\]
donde:
\(\circ \:𝑄_{1}\) 𝑦 \(𝑄_{3}\): hacen referencia al primer y tercer cuartil, respectivamente; la diferencia entre estos dos valores da como resultado el valor de espacio intercuartil (\(𝐼𝑄𝑅\)), y
\(\circ \:𝑀𝐶 (𝑚𝑒𝑑𝑐𝑜𝑢𝑝𝑙𝑒)\): cuantifica el grado de asimetría de una muestra univariable \({𝑥_1,𝑥_2,… ,𝑥_𝑛}\).
Se identifican los valores atípicos para cada conjunto de datos para cada año.
- Se itera sobre cada elemento de la lista
tablasque corresponden a los años2010y2020. - Se calculan los estadísticos de la columna del índice de marginación para cada conjunto de datos \(DP2_{i}\) correspondientes al año y se asigna el resultado a una nueva variable denominada \(outliers_i\).
for(i in tablas){
assign(paste0("outliers_", i), boxplot.stats(get(paste0("DP2_", i))[,22]))
}Se crea un data.frame que contiene el número de valores atípicos, su rango y el límite inferior para cada conjunto de datos.
| Límites para el cálculo de estratificación a nivel AGEB, 2010 | ||
| Mínimo | Límite | |
|---|---|---|
| Límites para el cálculo de estratificación a nivel AGEB, 2020 | ||
| Mínimo | Límite | |
|---|---|---|
Se identifican los casos extremos en el índice de marginación y se aplica el método de caja propuesto por Hubert y Vandervieren, concluyendo los límites con los que se debe trabajar.
Se añade una nueva columna IM_out. Esta columna se calcula usando if_else, de la siguiente manera:
- Si el valor de IM es mayor o igual al límite inferior de los valores no considerados outliers
(get(paste0("outliers_", i))$stats[1]), entoncesIM_outtoma el valor deIM.
- Si el valor de IM es menor que el límite inferior, entonces
IM_outtoma el valor del límite inferior, eliminando así los outliers.
## Se crea un índice ficticio, en la que se quitan los outliers
for(i in tablas){
assign(paste0("DP2_", i), get(paste0("DP2_", i)) %>%
mutate(IM = get(paste0("IM_", i))) %>%
mutate(IM_out = if_else(.$IM >= get(paste0("outliers_", i))$stats[1],
.$IM,
get(paste0("outliers_", i))$stats[1])) %>%
select(-paste0("IM_", i))
)
}Método de estratificación de Dalenius & Hodges
strata.cumrootf: cumulative root frequency method by Dalenius and Hodges (1959).
Con la obtención del índice de marginación a través del método DP2, los valores se clasificaron en cinco categorías ordinales con el método de Dalenius y Hodges (1959), para obtener el grado de marginación. Este método forma estratos de manera que la varianza sea mínima al interior de cada estrato y máxima entre cada uno de ellos, es decir, son lo más homogéneos posibles. Este procedimiento utiliza la raíz de las frecuencias acumuladas para la construcción de los estratos, por lo que se lleva a cabo para la división de la población en el estrato L. Esta es una solución aproximada de Dalenius y Hodges (1959) a las ecuaciones de Dalenius (1950). De acuerdo con Gunning y Horgan (2004), el límite superior de cada estrato se determinó con la siguiente expresión:
\[Q = \frac{1}{L}\sum^{J}_{i=1}{\sqrt{f_{i}}}\]
Sea un conjunto de estratos determinados por su límite superior,
\[Q,\ 2Q,\ \ldots,\ \left(L-1\right)Q,\ (L)Q.\] donde:
\(\circ \:J\): es el número de clases dentro del grupo de la variable ordenada X,
\(\circ \:f_{i}\ \in(1,\ \ldots, J)\): es la frecuencia en cada clase \(J\), y
\(\circ \:L\): es el número de estratos.
La eficiencia del método de la raíz de las frecuencias acumuladas depende principalmente del número de clases dentro del grupo de la variable ordenada. Sin embargo, no hay un procedimiento estándar sobre cómo elegir el mejor valor para el número de clases, siendo esto una limitante del método de Dalenius y Hodges. Para medir el efecto del número de clases en la varianza de cada estrato se recurrió a un método iterativo para obtener un criterio de agrupación óptimo.
Para establecer los límites de los estratos \((b_{1},\ \ldots,\ b_{L})\) que minimicen la varianza del estimador, se utiliza la asignación de Neyman para determinar el tamaño de muestra óptimo. Sea la varianza del estimador:
\[V\left({\bar{x}}_{st}\right)=\ \sum_{h}\left(\frac{N_h}{N}\right)^2\frac{S_h^2}{n_h}\ \] donde:
\(\circ \: S_{h}^{2}\): es la varianza poblacional en el estrato \(h\),
\(\circ \:n_{h}\): es el tamaño de muestra en el estrato \(h\) utilizada por la asignación de Neyman, y
\(\circ \:N_{h}\): es el total de elementos en el estrato \(h\), sea \(N=\sum_{h=1}^{L}{N_{h}}\).
Si se asume que la distribución dentro de cada estrato se distribuye aproximadamente de manera uniforme, los límites se obtienen tomando intervalos iguales en la función de la raíz de las frecuencias acumuladas. Los límites se resuelven de manera iterativa:
\[\frac{S_h^2+(b_h-{\bar{X}}_h)2}{S_h}=\frac{S_{h+1}^2+(b_h-{\bar{X}}_{h+1})2}{S_{h+1}}\ para\ h=1,\ \ldots.\ ,\ L-1\] donde:
\(\circ \: b_{h}\): es el límite superior en el estrato \(h\),
\(\circ \: {\bar{X}}_{h}\): es la media poblacional en el estrato \(h\), y
\(\circ \: S_{h}^{2}\): es la varianza poblacional en el estrato \(h\).
El requisito de precisión, generalmente se establece cuando el coeficiente de variación sea igual a un nivel especificado entre 1 y 10 por ciento (Hidiroglou y Kozak, 2018).
Número óptimo de clases del método de Dalenius & Hodge
alloc lista que especifica el esquema de asignación. La lista debe contener 3 números para los 3 exponentes q1, q2 y q3 en el esquema de asignación general (ver paquete de stratification). El valor predeterminado es la asignación de Neyman (q1 = q3 = 0.5 y q2 = 0)
A continuación, se realiza un análisis de estratificación sobre los diferentes años, usando la función strata.cumrootf(), almacenando los resultados de errores estándar, medias y varianzas en matrices que luego se guardan en listas.
iteraciones <- 1000
start.time <- Sys.time()
DH_AGEB <- list()
stderr <- list()
mean <- list()
var <- list()
for(j in 1:2){
i <- 1
sd <- matrix(NA, nrow = (iteraciones), ncol = 3)
meanh <- matrix(NA, nrow = (iteraciones), ncol = 6)
varh <- matrix(NA, nrow = (iteraciones), ncol = 6)
for(n in seq(5, (iteraciones), 1)){
DH_AGEB[[paste(tablas[j])]][[n]] <- strata.cumrootf(x = get(paste0("DP2_", tablas[j]))[,23], CV = 0.05, Ls = 5, alloc = c(0.5, 0, 0.5), nclass = n)
cum <- DH_AGEB[[paste(tablas[j])]][[n]]
sd[i,] <- c(n, cum$stderr, cum$CV)
meanh[i,] <- c(n, cum$meanh)
varh[i,] <- c(n, cum$varh)
i <- i + 1
}
stderr[[j]] <- sd
mean[[j]] <- meanh
var[[j]] <- varh
}
for(i in 1:2){
colnames(stderr[[i]]) <- c("n", "sderr", "CV")
}
end.time <- Sys.time()
time.taken <- round(end.time - start.time, 2)
time.takenNúmero óptimo de clases
Se toma cada matriz resultante de errores estándar de la lista stderr, y luego selecciona la fila que tiene el coeficiente de variación (CV) más bajo. Estos resultados se almacenan en la lista min.strata, la cual contendrá los data.frames correspondientes a las filas con el menor CVpara cada uno de los tres conjuntos de datos en stderr.
min.strata <- NULL
for(i in 1:2){
min.strata[[i]] <- stderr[[i]] %>%
as.data.frame() %>%
slice(which.min(.$CV))
}| Número óptimo de clases | |||
| AÑO | n | sd | C.V. |
|---|---|---|---|
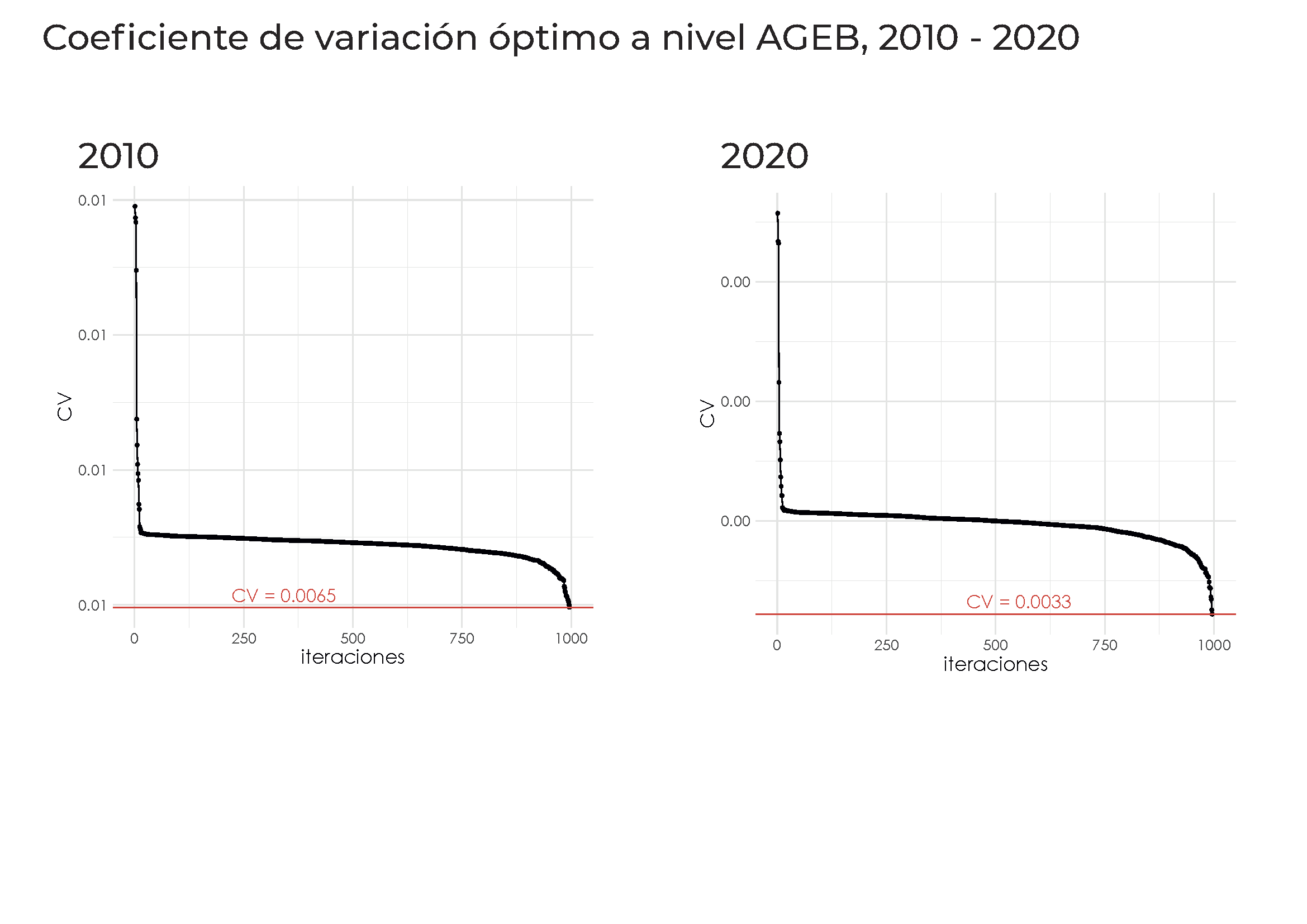
Se toman en cuenta el número de clases que salen del los resultados del método iterativo. Utilizando la función strata.cumrootf() de la paquetería stratification con parámetros específicos y el número de clases (nclass) obtenido de min.strata.
- CV = 0.05: Establece el coeficiente de variación.
- Ls = 5: Establece el número de estratos.
- alloc = c(0.5, 0, 0.5): Define la asignación para la estratificación.
- nclass = min.strata[[i]][,1]: Establece el número de clases utilizando el primer valor de la fila con el menor CV en min.strata.
for(i in 1:2){
assign(paste0("strata.DP2_", tablas[i]), strata.cumrootf(get(paste0("DP2_", tablas[i]))[,23],
CV = 0.05,
Ls = 5,
alloc = c(0.5, 0, 0.5),
nclass = min.strata[[i]][,1]))
}Se agregan los datos a la base original
##Se agrega a la base DP2
for(i in 1:2){
assign(paste0("DP2_", tablas[i]), data.frame(get(paste0("DP2_", tablas[i])) %>%
select(-IM_out), # Se quita el índice ficticio
get(paste0("strata.DP2_", tablas[i]))[["stratumID"]]))
}
# Se cambian los nombres de las columnas
for(i in 1:2){
columns = get(paste0("DP2_", tablas[i]))
colnames(columns) = c("CVE_AGEB", "ENT", "NOM_ENT", "MUN", "NOM_MUN", "LOC", "NOM_LOC", "AGEB", "POB_TOTAL", "AÑO",
"P6A14NAE", "SBASC", "PSDSS", "OVSDE", "OVSEE", "OVSAE", "OVPT", "OVHAC","OVSREF", "OVSINT", "OVSCEL",
paste0("IM_", tablas[i]), paste0("GM_", tablas[i]))
assign(paste0("DP2_", tablas[i]), columns)
rm(columns)
}
# Se cambian los levels a los grados de marginación correspondientes
for(i in tablas){
niveles = get(paste0("DP2_", i))
levels(niveles[,23]) = c("Muy alto", "Alto", "Medio", "Bajo", "Muy bajo")
assign(paste0("DP2_", i), niveles)
}Límites de los estratos
Se crea un data frame llamado limites que contiene los límites de ciertos intervalos para los años 2010 y 2020. Cada columna contiene una combinación de:
- El valor mínimo del índice de marginación (IM:) para el año correspondiente.
- Los valores de los límites de los estratos (bh) calculados previamente.
- El valor máximo del índice de marginación (IM_) para el año correspondiente.
limites <- data.frame("2010" = c(min(DP2_2010$IM_2010), strata.DP2_2010$bh, max(DP2_2010$IM_2010)),
"2020" = c(min(DP2_2020$IM_2020), strata.DP2_2020$bh, max(DP2_2020$IM_2020)))| Límite de los estratos | |||||
| Muy alto | Alto | Medio | Bajo | Muy bajo | |
|---|---|---|---|---|---|
| 2010 | |||||
| 2020 | |||||